7 Understanding Data
1. Unit Objectives
In this unit we will discuss the essential features of data DOC1 Series 5 will use.
2. Essential Features of Sample Data
Accuracy
The sample data file must contain an example of every type of record and data field that may be encountered in the application data. If the sample data file is not complete, DOC1 Generate will fail when it encounters unrecognized data during production.
3. Supported Data Structures
DOC1 Series 5 supports three general types of input data:
Keyed Records
A line data or 'flat' file where each line is an individual record. Record types are identified according to the contents of a field within each line of data (the key field). Other fields within the records must be individually identified. You will need to supply a sample data file that acts as the template on which the record and field definitions are built.
4. Production vs. Sample Data
Production data
Your production is the sum total of all information you need to create a complete set of documents. It will include data such as customer name, account number, billing totals, etc. It must also be formatted in one of the ways that can be read by Series 5.
Sample data
The sample data file, in contrast, is a subset of the production data. It is a smaller set of data that still has one example of every field and record that will be present in the production data.
The sample data file often plays two roles. First, it is used to provide the description of the data to Series 5. Second, it is often used as a basic test sample. Since there may be a conflict between these two goals, it is often advisable to have two separate files.
5. Editing a Sample Data File
In this section we will look at a sample data file and edit the last data record to reflect your information.
6. Sample Data
Sample data is variable information from your business environment that can be used as part of your documents. DOC1 Generate uses sample data files that contain a set of information for each publication to be produced. Typically this is a database extract that has been prepared for use with Series 5.
The sample data file consists of data records and data fields. Broadly speaking there are two types of data elements:
Non-repeating
Data typically contains information such as account numbers, names, addresses and so on. Fields that contain non-repeating data appear only once in the sample data for a single publication and can be used directly within paragraph text.
Repeating
Data typically contains transaction type information such as account entries or itemized telephone calls. Repeating data is iterated within the data for a single publication - i.e. the same data structure appears multiple times consecutively. The data structure itself can consist of one or many elements that each need to be referenced as a separate data field when used in a document design.
Series 5 supports the following sample data files: *.xml, *.svd, *.dat, *.txt, *.csv, *.lin and *rdi.
We are going to import our ResponseSample.svd file to our Company Letters project folder.
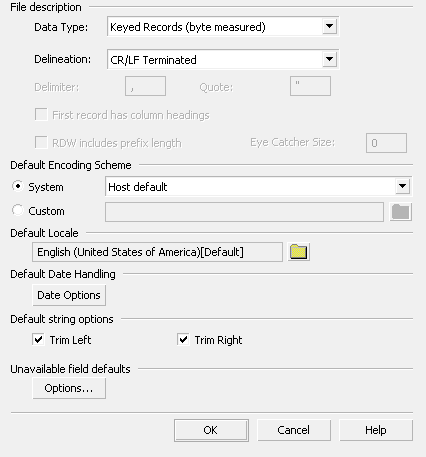
Data Type
There are three Data Types: Keyed Records , Delimited and XML.

If we choose Keyed Record we are telling Series 5 that each distinct record type is labeled with a name. The name is a simple text field and can be any size, and can be located at any position in the record. However, it must be located at the same position and be the same length in every record in the database.
If we choose XML, we are telling Series 5 that the input data conforms to the XML standard.
Delineation
The delineation type allows Series 5 to determine when it has come to the end of a record. You have the following choices:

CR/LF Terminated: this means that each record in the database has two characters at the end - a carriage return and a line feed, or a hex 0D and a hex 0A. Typically, data brought over from a PC will have this kind of format.
LF Terminated: this means that each record in the database has one character at the end - a line feed, or a hex 0A. Typically, data brought over from a UNIX machine will have this kind of format.
LSB/MSB Ordered RDW: this means that each record starts with two bytes that give a numeric value - the length of the record in bytes. LSB stands for Least Significant Byte, and MSB stands for Most Significant Byte. Typically, data brought over from a mainframe computer will have this kind of format.
Default encoding scheme
All data needs to be interpreted using a system code page. This allows applications to understand the intended strings and values within the binary encoding that makes up the data itself. Use this option to identify the code page that will, by default, be assumed for interpreting the input data being imported. Note that parts of your data may use different encoding schemes (in particular, where text is based on multiple languages that use different code pages) so Series 5 allows you to override this default for each individual field if required.
Default Locale
This option allows you to specify a default locale to be used to determine regional delimiters within number and date fields. It can be overridden for individual field definitons if required.

Default Date Handling
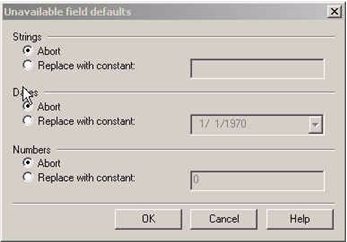
This is where you show Series 5, if your data contains date fields, how to handle incomplete or invalid date values. In particular, you may want to customize how two digit year values are interpreted.

Default String Option
This option allows you to globally trim spaces left and right. You can override this setting on a individual field level if necessary.